BGINFO - A Posh Recreation
Recently I have been building a lot of Windows Servers in different environments - one
As part of my ongoing training I have been fortunate enough to start down the road towards an MSc in Forensic Computing for Practitioners with De Montfort University, Leicestershire. We have been taught by 2 outstanding Professors, Prof B Jenkinson and Prof A Sammes, one of which was involved in RFC1 back in 1969!
As part of this course one of the modules is regarding the forensic examination of internet use and as such involves the examination of a recovered Google Chrome cache. I have just completed the first question in the coursework, which is to explain what the Chrome Cache is and how it works and felt it would be ideal content for my second blog post so here I go 🙂
A cache is a system used by a browser to enable faster loading of web pages which have been visited the next time they are requested. So they are effectively a record of sites already visited. The cache for the Google Chrome browser is all stored within
AppDataLocalGoogleChromeUser DataDefaultCache
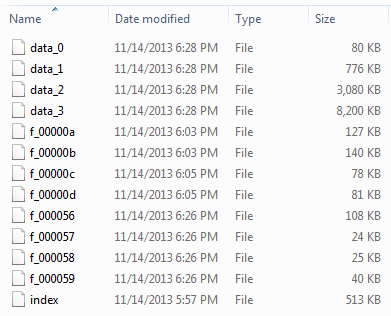
The structure of the cache folder looks as follows:

The cache consists of at least 5 files, an Index and 4 data files. Data files from websites visited will be stored within one of the 4 data files if they are under 16kb in size. Files which are larger than that will begin to be stored within the cache folder and titled with a filename beginning f_ followed by a 6 digit hex number.
The index file is effectively a map which contains the cache address linking a hash value of the key (URL) to an Entrystore entry within one of the data files for the requested resource. We are able to reverse engineer our way to this value from an f_ file if one was recovered.
All cached objects have an address and this is a 32 bit number which describes where the object is stored.
So for example if we wanted to calculate the cache address for a separate file we had located within the cache titled f_000056 we would do the following:
|
1
|
000
|
0000 0000 0000 0000 0000 0101 0110
|
When the binary representation above is converted to hex we have 80000056h which we convert to little endian as 56000080h.
Now we have our cache address for this external file we will use that to find the metadata contained within one of the data stores. I use a program called winhex to view each of the data stores in hex format and carrying out a hex search for 56000080h I found one hit within data_1:

The information contained within this metadata will be fully explained in a later blog but we can see reference to a .jpg. With this in mind f_000056 when opened with a graphics viewer such as irfanview shows us:

The following diagram shows the overall structure of the cache:

The rankings mentioned within the diagram relates to the system used for knowing when an entry should be evicted from the cache and not of any real forensic value in this instance. The other terms will be further expanded in future blogs on this subject.
I plan to use the further questions as content for upcoming blogs and these will detail how it is possible to reconstruct a webpage from the cache and also how we can trace back through the cache explaining how a user arrived at that final picture.
I hope this has made sense and if you have any feedback or spot any errors I gladly accept the advice and guidance of my peers in the comments below. Thanks for taking the time to read this blog entry.